Liv Gorton
[Preprint] Adversarial Examples Are Not Bugs, They Are Superposition
Work conducted at Goodfire and co-written with Owen Lewis. Full preprint here. Last updated August 26th, 2025.
Abstract
Adversarial examples—inputs with imperceptible perturbations that fool neural networks—remain one of deep learning’s most perplexing phenomena despite nearly a decade of research. While numerous defenses and explanations have been proposed, there is no consensus on the fundamental mechanism. One underexplored hypothesis is that superposition, a concept from mechanistic interpretability, may be a major contributing factor, or even the primary cause. We present four lines of evidence in support of this hypothesis, greatly extending prior arguments by (Elhage et al., 2022): (1) superposition can theoretically explain a range of adversarial phenomena, (2) in toy models, intervening on superposition controls robustness, (3) in toy models, intervening on robustness (via adversarial training) controls superposition, and (4) in ResNet18, intervening on robustness (via adversarial training) controls superposition.
Introduction
Adversarial examples represent one of the most perplexing phenomena in deep learning: neural networks that achieve superhuman performance on many tasks can be fooled by perturbations so small they are imperceptible to humans. Despite nearly a decade of intensive research and many different hypotheses, there is no widely accepted explanation. In this paper, we explore an alternative hypothesis: superposition.
Superposition is a concept from the mechanistic interpretability literature. At a high level, superposition exploits the geometry of high-dimensional spaces to allow neural networks to represent more features than they have neurons. However, this strategy comes at a cost. Features in superposition necessarily interfere. On distribution, this interference is small, but in worst-case scenarios, it can be significant. One of the foundational papers on superposition hypothesized this interference could be linked to adversarial examples (Elhage et al., 2022), yet this hypothesis remains unexplored.
Our primary contribution is three experiments testing the relationship between superposition and robustness, in both toy models an ResNet18. These experiments are summarized in Figure 1. For toy models, we demonstrate both that superposition can control robustness, and that robustness can control superposition. For ResNet18, we show only that robustness can control superposition. (Unfortunately, without a method for controlling superposition in real models, we are unable to demonstrate the other direction in real models.)
Combined, these results strongly imply that superposition is at least one causal factor in the existence of adversarial examples. They don’t necessarily suggest that it’s the only factor, as we can’t intervene on superposition in real models to isolate this.
At the same time, we take seriously the possibility that it might be the primary explanation. Although it isn’t the primary focus of this paper, it seems to us that superposition is sufficient to theoretically explain all the adversarial phenomena we’re aware of. This is summarized in Table 1.
| Phenomenon | Superposition Explanation |
|---|---|
| Existence: Adversarial examples exist across essentially all neural networks (Szegedy et al., 2014; Goodfellow et al., 2015) | Features can be attacked by perturbing all the features in superposition with them. An attacker can do this iteratively at each layer. |
| Noise-like structure: Adversarial perturbations appear as unstructured high-frequency noise rather than semantic patterns (Goodfellow et al., 2015; Sharma et al., 2019) | Adversarial attacks work by attacking many features, which are totally unrelated except for the fact that they’re in superposition with the actual targets. |
| Attack Transferability: Adversarial examples transfer between independently trained models (Goodfellow et al., 2015; Liu et al., 2017) | If the same features are in superposition with each other, attacks based on superposition will transfer. Features which are anti-correlated are preferentially put in superposition with each other (Elhage et al., 2022) and therefore attacks should transfer. |
| Training difficulty: Adversarial training is fundamentally difficult, requiring significant computational resources and degrading natural accuracy (Madry et al., 2019) | Superposition increases the capacity of models. If improving model robustness requires reducing superposition, that fundamentally reduces model capacity. |
| Interpretability: Adversarially trained models become markedly more interpretable with neurons that correspond to human-understandable concepts (Engstrom et al., 2019) | In the absence of superposition, neurons can be monosemantic, and also less noisy. |
| Training on Attacks Transfers Clean Performance: Training on mislabeled data with adversarial attack towards the erroneous label induces correct behavior on clean data (Ilyas et al., 2019) | Training on adversarial attacks transfers to clean data because adversarial attacks encode interfering combinations of genuinely useful circuits. |
Background
The mechanistic interpretability literature often assumes that model representations are linear. That is, the hidden activations \(h\) of some layer can be understood as \(h=\sum_{i<k} a_i \vec{f_i} + \vec{b}\) where \(k\) is the total number of features, \(a_i\) is the activation of a feature \(i\), and \(f_i\) is a direction in activation space representing that feature. Roughly, activation represents the intensity or strength of a feature in response to a particular input.1
One might expect that if a neural network representation has \(n\) dimensions, it can only represent \(k\leq n\) linear features. However, results from an area of mathematics called compressed sensing suggest that neural networks could represent many more features (\(k>>n\)), so long as features are sparse (that is, zero on most examples). This is called the superposition hypothesis.
Superposition necessarily entails interference. When \(k > n\) features are represented in an \(n\)-dimensional space, the feature vectors \(\{\vec{f}_i\}_{i=1}^k\) cannot all be mutually orthogonal. This non-orthogonality means that activating feature \(i\) with coefficient \(a_i\) produces (apparent) spurious activations in feature \(j\) proportional to \(a_i \langle \vec{f}_i, \vec{f}_j \rangle\). Models can partially compensate for this interference by learning negative biases \(b_j < 0\) that suppress small spurious activations below a threshold. However, this compensation mechanism assumes the total interference \(\sum_{i \neq j} a_i \langle \vec{f}_i, \vec{f}_j \rangle\) remains bounded. In worst-case scenarios, an adversary can coordinate activations to make this sum arbitrarily large, overwhelming the bias term. (This aligns with compressed sensing theory, which only guarantees reconstruction with high probability under random, not adversarial, conditions.)
(Elhage et al., 2022) demonstrated that this interference mechanism enables adversarial attacks in toy models. Specifically, consider a target feature \(\vec{f}_{\text{target}}\) in superposition with features \(\{\vec{f}_1, \ldots, \vec{f}_m\}\) where \(\langle \vec{f}_{\text{target}}, \vec{f}_i \rangle = \epsilon_i \neq 0\). An adversary can exploit this by adding input perturbations that activate each interfering feature by a small amount \(\delta_i\). While each individual contribution \(\delta_i \epsilon_i\) to the target feature’s activation is negligible, the cumulative effect \(\sum_{i=1}^m \delta_i \epsilon_i\) can be made arbitrarily large by choosing appropriate \(\delta_i\) values (subject to the perturbation budget). This is precisely the interference that models attempt to suppress through learned biases under normal operating conditions.
This vulnerability compounds across layers. At each layer, the adversary can exploit superposition to create unwanted feature activations, which then propagate to the next layer as inputs. These corrupted activations at the next layer can then be constructed to do the same kind of attack, allowing errors to accumulate through the network.
Causal Evidence from Toy Models of Superposition
To test whether superposition causally contributes to adversarial vulnerability, we extend the toy models of (Elhage et al., 2022), the standard theoretical model of superposition. In the toy model setup, it is possible to exactly measure superposition, which is not possible in real models because it requires knowledge of the ground truth features learned by the model. It also allows us to control superposition by manipulating feature sparsity. This will allow us to show both that superposition controls robustness and that robustness controls superposition in the toy models setup.
Setup
Toy Models
We consider a simplified2 version of the basic setup of (Elhage et al., 2022). Our data consists of \(n=100\) features. They are linearly projected into a \(m=20\) hidden units, \(h=Wx\), and then reconstructed by a ReLU layer, \(x' = \text{ReLU}(W^T x + b)\). The loss is mean squared error.
The behavior of this toy model varies based on the feature sparsity, \(S\). This is the probability that the input features are zero. When features are sparse, this setup exhibits superposition, representing more features than there are hidden dimensions. The amount of superposition increases with sparsity.
Measuring Superposition
One reason for our interest in the toy model setting is that superposition can be exactly measured. One way to do this is by looking at the features per dimension (Elhage et al., 2022), i.e., how many features the model is attempting to represent per feature dimension:
\[\frac{||W||_F^2}{n}\]This works because features are roughly represented with unit norm when learned. When the features per dimension \(>1\), the model must be using superposition, as it represents more features than it has dimensions.
Measuring Robustness
We also need to know how vulnerable our models are to adversarial examples. To measure adversarial vulnerability, we generate \(L_2\)-bounded adversarial examples. For each input \(x\), we find the worst-case perturbation within an \(\epsilon\)-ball that maximizes reconstruction error:
\[x_{adv} = x + \epsilon \cdot \arg\max_{\|\delta\|_2 \leq 1} \mathcal{L}(x + \epsilon \delta)\]We set \(\epsilon\) to 10% of the average input norm.
We reproduce the approach of (Elhage et al., 2022), who exploit the toy model setup to analytically construct attacks that optimally attack each specific output feature, and then take the worst such attack. They take this approach to avoid gradient masking issues from ReLU. However, while this would be an optimal attack in terms of \(L_\infty\) in the output space, it has the potential to be quite suboptimal for affecting the output as measured by \(L_2\)/MSE. For this reason, we primarily consider a more traditional adversarial attack. We add a small amount of noise to avoid gradient issues, and then do a one-step gradient L2 attack. All results in the main paper are based on this attack.
To compare the vulnerability of models, we consider how many times more vulnerable it is than a model without superposition (i.e., our model with the highest input feature density, with every feature present in all training inputs).
Adversarial Training Protocol
Since we want to test whether causality flows from adversarial robustness to superposition, we also need to be able to produce adversarially robust versions of our toy models. To do this, we train new toy models over the same range of feature densities, but using a mixture of clean and adversarial training examples:
\[\mathcal{L}_{adv} = \alpha \cdot \mathcal{L}(x) + (1-\alpha) \cdot \mathcal{L}(x_{adv})\]where \(\alpha = 0.5\) balances clean and robust accuracy. We use \(L_2\) attack with \(\epsilon = 0.1 \|x\|_2\). We can generate these attacks on-the-fly using either approach from the previous section, but unless otherwise specified, we use the more standard gradient attack rather than the Elhage method. We train a model with the same configuration as the model used in Section 3.1.1 for 150,000 steps with a learning rate \(10^{-3}\). (This follows a common practice in adversarial training where models are trained for extended periods compared to standard training due to the unique optimization dynamics; see e.g., (Rice et al., 2020) for discussion of adversarial training dynamics.)
Intervening on Superposition Controls Adversarial Vulnerability
We use feature sparsity to manipulate the level of superposition, and observe resulting changes in adversarial robustness. In particular, we vary the feature density \((1 - \text{sparsity})\) exponentially from 1.0 to 0.1, training 30 models simultaneously with different sparsity levels, and observe the resulting adversarial robustness. This is the general setup of (Elhage et al., 2022), but we focus on more powerful noise-plus-gradient adversarial attacks. (A reproduction of the original Elhage experiment can be found in the appendix, see Figure 6.)
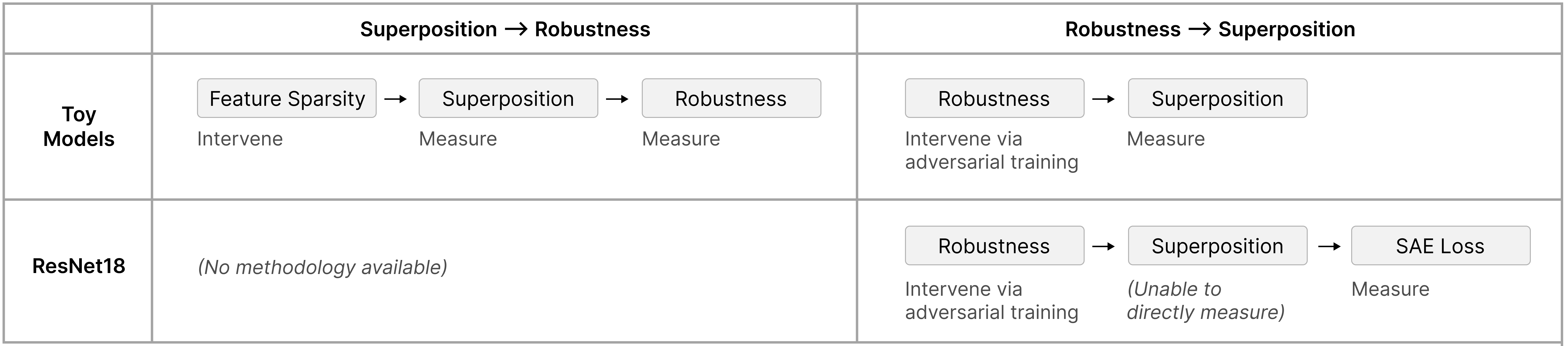
Our first goal is to confirm that intervening on feature sparsity has the expected effect on superposition, in order to validate it as a way to manipulate superposition in our larger experiment. Panel A of Figure 2 shows the expected results, including a temporary plateau corresponding to antipodal superposition.
Having validated our instrumental variable, we now proceed to the core result. Panel B of Figure 2 shows that adversarial vulnerability increases with both feature sparsity and superposition (quantified as features per dimension). There is one striking dip corresponding to antipodal superposition.
The mechanism is intuitive: when features are in superposition, they share directions in activation space. An adversary can exploit this by perturbing all interfering features simultaneously. Since features in superposition are not orthogonal, small perturbations to many features accumulate into large changes in the target feature’s reconstruction.
It is worth noting that there is some subtlety to comparing adversarial robustness across different feature densities, since the distribution we are evaluating on changes. However, this should, if anything, bias in the opposite direction of the trend we’re observing. Having fewer features active should tend to make models more robust, since fewer ReLUs would be open, allowing gradients through. Thus, we believe this concern would cause us to underestimate the relationship between superposition and adversarial vulnerability. However, we do get some cross-validation from the robust models in the next section, since these shift superposition independently of the data distribution, and we still see the same trend.
Intervening on Adversarial Robustness Controls Superposition
To establish bidirectional causality, we next ask: does improving adversarial robustness reduce superposition? We perform adversarial training on our toy models and measure the resulting changes in superposition.
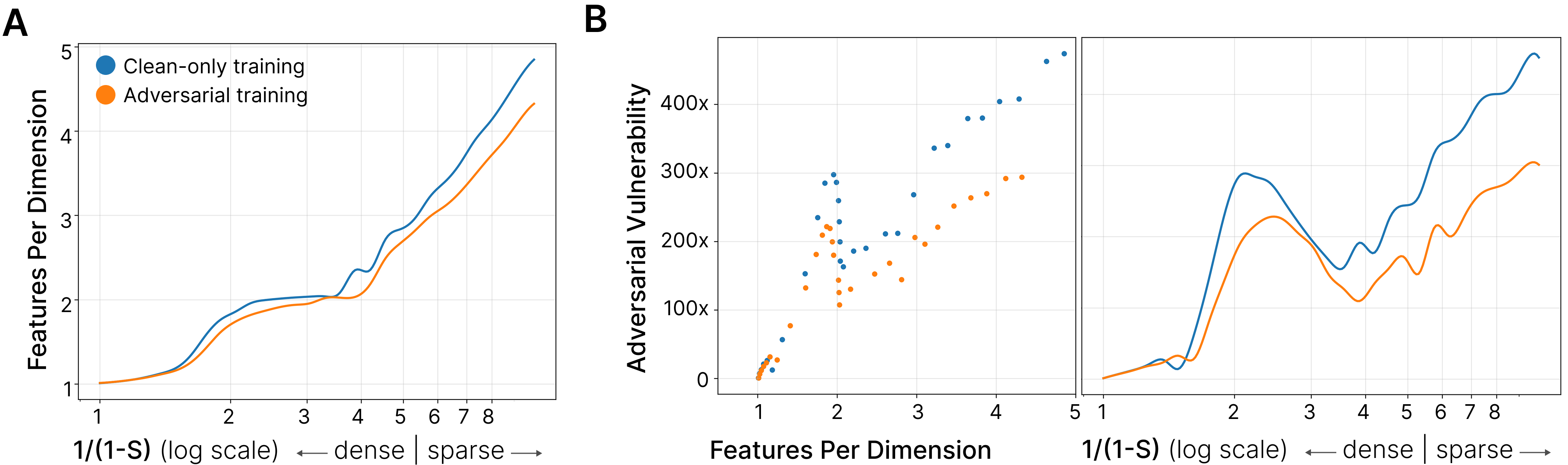
Figure 2 demonstrates that adversarial training reduces superposition. Models that underwent adversarial training decreased their adversarial vulnerability and decreased features per dimension for some original input sparsity. However, we note two surprising phenomena. Firstly, as discussed earlier, we note a drop in vulnerability to adversarial examples when models switch to antipodal superposition. Secondly, we note that robust models are often more robust than expected for their superposition level. Our interpretation is that the overall level of superposition doesn’t tell the full story; we conjecture that some superposition structures (that is, the matrix of interference between features) are more or less vulnerable to superposition. See Discussion (section 6).
In contrast to the previous section, where we reproduced and extended the results of (Elhage et al., 2022), to the best of our knowledge, these results are the first to demonstrate causality from robustness to superposition.
Theoretical Intuition
While not a formal derivation, we find it useful to conceptualize the difference between standard and adversarial training through the lens of interference minimization.3
Given dataset \(\mathcal{D}\), neural network parameters \(\theta\), and a measure of interference \(I\), we might conceptualize neural network training as:
\[\min_\theta \mathbb{E}_{(x, y) \sim \mathcal{D}}[I(x, y; \theta)]\]That is, the goal is to minimize the average expected interference. Whereas during adversarial training, it might be better instead to conceptualize the objective with respect to interference as:
\[\min_\theta \max_{\mathcal{D} \in \mathcal{D}_{\text{OOD}}} \mathbb{E}_{(x, y) \sim \mathcal{D}}[I(x, y; \theta)]\]That is, the goal is to minimize the maximum expected interference over out-of-distribution data.
This conceptualization suggests that adversarial training forces the model to consider worst-case interference patterns rather than average-case, potentially explaining why it reduces superposition in our experiments.
Adversarial Examples Exploit Feature Interference
We constructed superposition geometry graphs similarly to (Elhage et al., 2022), where each feature has a node, and edge \((i, j)\) represents \((W_i \cdot W_j)^2\).
These graphs can then be used to understand how this geometry is being exploited in adversarial attacks, and subsequently why a model is adversarially robust.
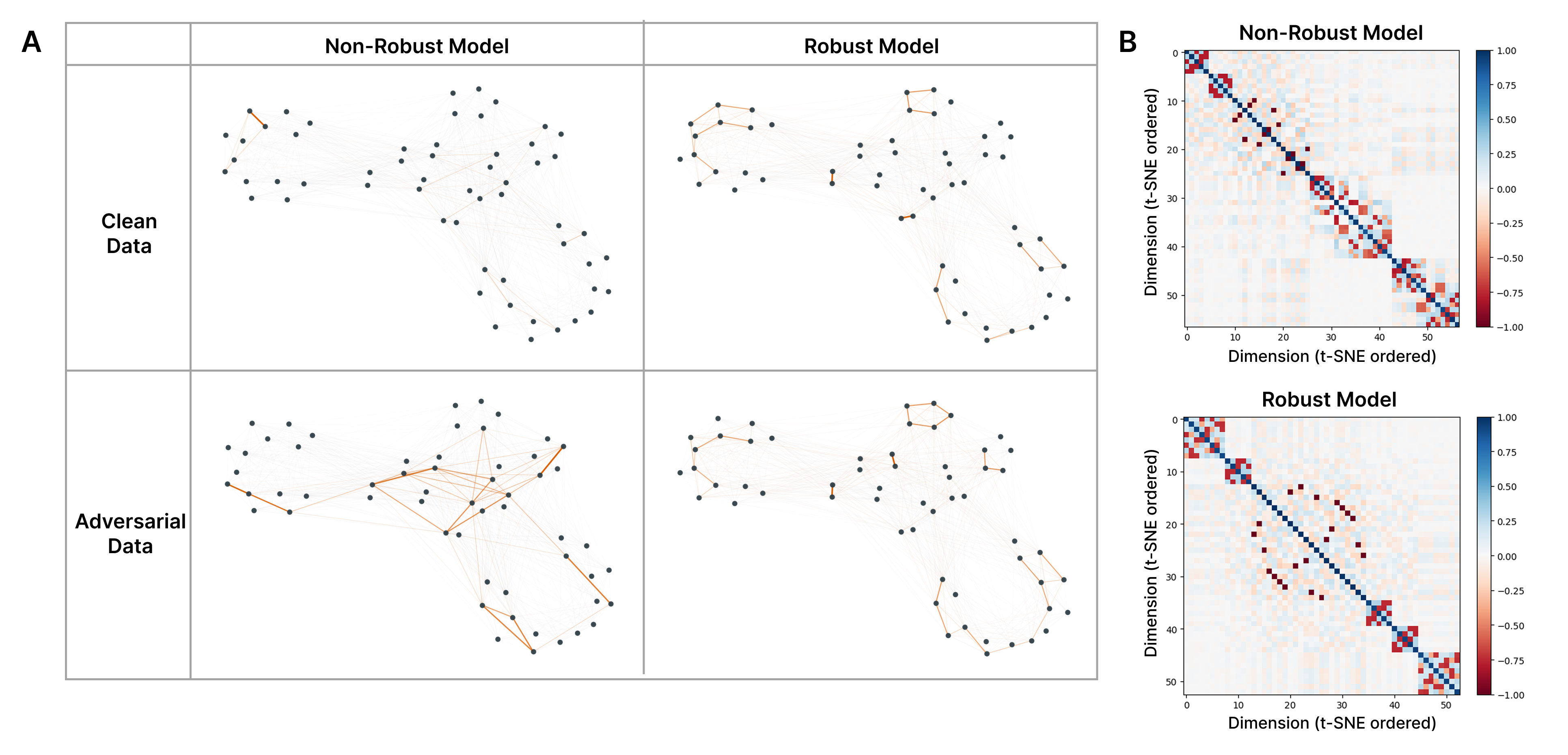
Figure 3 illustrates how adversarial attacks exploit feature interference patterns. In non-robust models (left column), clean inputs activate relatively few features with minimal interference between them, as shown by the sparse orange highlighting in the superposition graph. Adversarial inputs, however, activate many interfering features simultaneously, precisely the pattern expected if attacks exploit superposition geometry. In contrast, robust models (right column) show similar sparse activation patterns for both clean and adversarial inputs, suggesting that adversarial training has reorganized the feature geometry to prevent interference-based attacks. The heatmaps in panel (B) confirm this: non-robust models exhibit mean off-diagonal interference approximately 2× that of robust models, indicating denser superposition structure.
Superposition Geometry
We can also use the graph visualization technique to compare a larger set of models. In Figure 4, we look at pairs of non-robust and robust models trained at the same sparsity level. The robust models have less superposition (corresponding to a further left position) but strikingly similar superposition geometries.
Evidence From Real Models
We now turn our attention to real models. Unfortunately, since we have no way to intervene on superposition in real models, we can’t test the causal effect of superposition on robustness. However, we can still adversarially train models to control robustness and observe the effect on superposition via the proxy of sparse autoencoder loss (discussed further in Section 4.2)
Methods
Adversarially Robust Models
To study adversarial robustness in real models, we used robust ResNet18s trained on ImageNet (Russakovsky et al., 2015) from (Salman et al., 2020).4 These robust models are trained against different attack sizes, varying their robustness.
Sparse Autoencoders
We train sparse autoencoders (SAEs) on the outputs of ResNet18’s four residual stages (conv2_x through conv5_x), which produce 256-, 512-, 1024-, and 2048-dimensional feature maps at progressively lower spatial resolutions. We trained both L1 ReLU SAEs (Conerly et al., 2024) and TopK SAEs (Gao et al., 2024) on standardized activations to mitigate the effect on training of activation statistics. Additional training details can be found in Appendix A.
Robust Models Achieve Better SAE Reconstruction
There is no direct way to measure the amount of superposition in real models, and so instead we must consider proxies of superposition.
SAEs are designed to model superposition and will naturally have a higher loss when there is more superposition. There are several reasons for this: (1) if a model of a fixed size has more superposition, it has more total features that an SAE has to model, (2) with more total features, there will also be more active features on any example, (3) in denser superposition, the SAE will be forced to either sometimes model a strongly activating feature as activating other features, or sometimes not represent small activations.
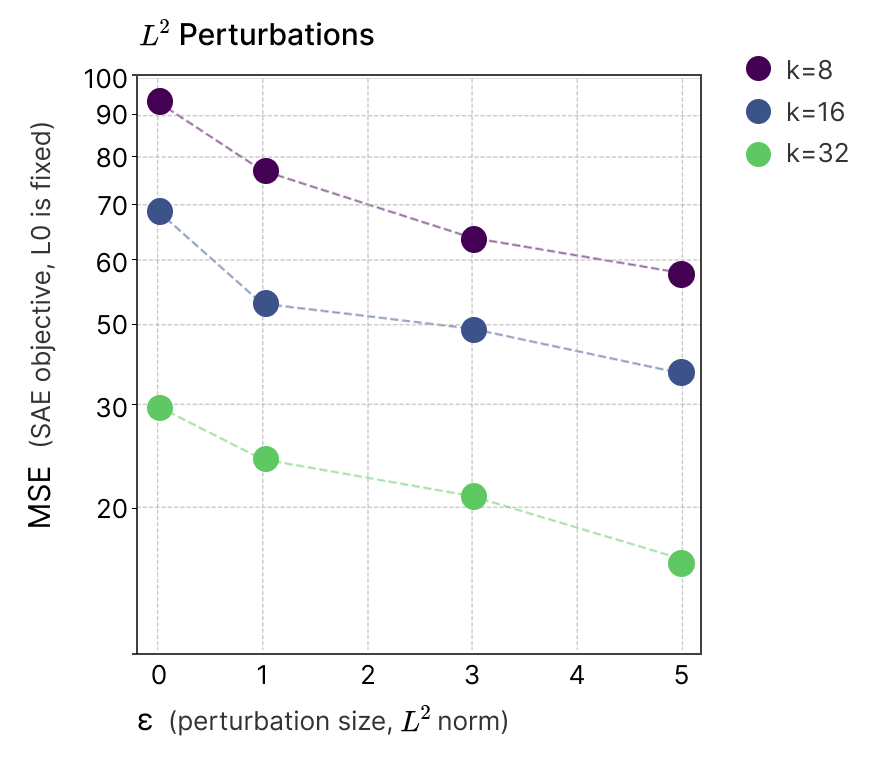
Figure 5 shows that for a given sparsity level, more robust models consistently achieve better reconstruction loss. Does this imply robustness effects superposition? The only way we see to avoid this is if some other change to the model could lower SAE loss independent of superposition, and we don’t have any hypotheses for what that could be.5
Adversarial Examples Increase L0
Our sparse autoencoders provide the opportunity for an additional experiment. If adversarial attacks do exploit interference, we’d expect them to activate more features. Each feature can both be attacked via interference and used to attack later features.
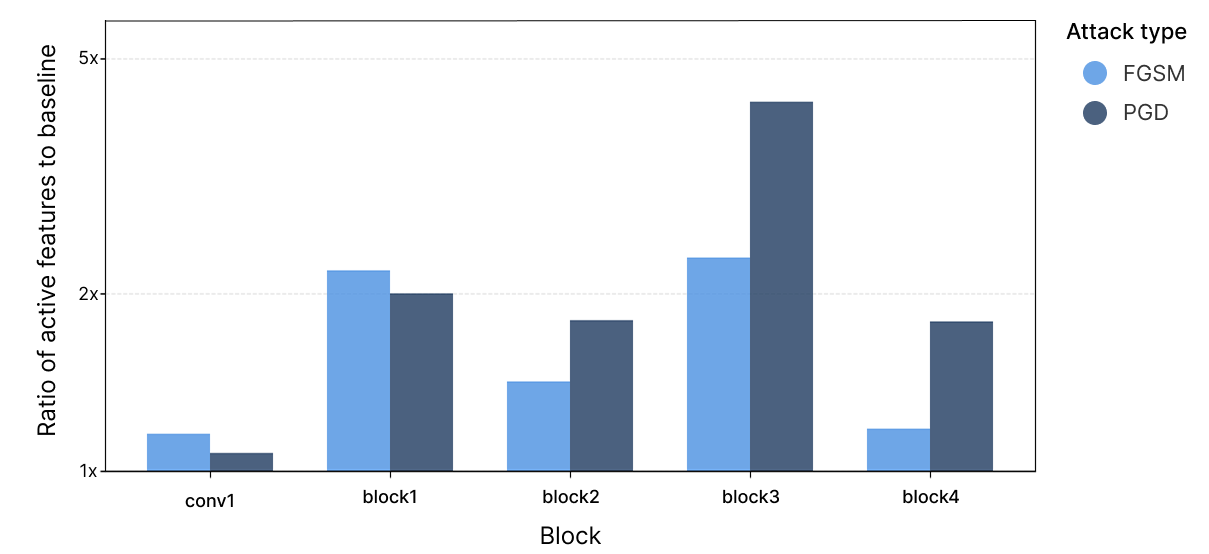
In Figure 6, we observe that the number of active features on adversarial attacks (using FGSM (Goodfellow et al., 2015) and PGD (Madry et al., 2019)) significantly exceeds the baseline, increasing throughout the model. Immediately after the first layer, we observe an increase of 1.1x, increasing to 2x after block 1, 1.5x after block 2, and peaking at 2-4x (depending on attack type) after block 3.
Discussion
We have argued that adversarial examples are caused, at least in part, by superposition. Beyond the theoretical arguments, three lines of empirical evidence support this hypothesis: (1) in toy models, superposition controls robustness, (2) in toy models, robustness controls superposition, and (3) in real models, robustness controls superposition.
While these arguments appear compelling, several limitations warrant consideration. First, our analysis relies substantially on proxy variables to control and measure effects, particularly in real models. These proxies may fail to capture the full complexity of the phenomena. Second, our experimental results could be consistent with adversarial examples having multiple causal factors beyond superposition, especially in real models. Without methods to directly manipulate superposition in real models and observe resulting changes in robustness, we cannot quantify the relative magnitude of superposition’s contribution, only establish the potentiality of a causal relationship. Despite these limitations, the evidence strongly suggests that superposition constitutes a major factor in adversarial robustness. Further confidence in this hypothesis will require developing more sophisticated tools for measuring and manipulating superposition in real models.
Several unexpected findings merit further investigation: (1) the temporary improvement in robustness observed near antipodal superposition configurations, and (2) the observation that models with equivalent overall superposition levels but different superposition structures exhibit varying robustness to L2 adversarial attacks. These phenomena warrant deeper theoretical and empirical examination.
If superposition represents a primary cause of adversarial examples, this implies a fundamental and unavoidable trade-off. Superposition enables models to effectively simulate substantially larger sparse models; achieving robustness would necessitate sacrificing this computational advantage. Conversely, this relationship would indicate a profound alignment between the objectives of interpretability and robustness research.
Related Work
Adversarial Examples. Since their discovery (Szegedy et al., 2014; Goodfellow et al., 2015), numerous attacks emerged (Moosavi-Dezfooli et al., 2015; Carlini & Wagner, 2016; Madry et al., 2019; Croce & Hein, 2020), extending to physical (Kurakin et al., 2016) and universal perturbations (Moosavi-Dezfooli et al., 2017).
Theoretical Explanations. Beyond the linear hypothesis (Goodfellow et al., 2015), explanations include geometric perspectives (Gilmer et al., 2018; Khoury & Hadfield-Menell, 2019; Shafahi et al., 2020; Shamir et al., 2022), concentration of measure (Mahloujifar et al., 2018; Mahloujifar et al., 2019), high-dimensional inevitability (Tanner et al., 2024), and manifold analyses (Xiao et al., 2022). The “robust features” hypothesis (Ilyas et al., 2019) suggests models exploit non-robust but predictive patterns.
Defenses. Adversarial training remains dominant (Madry et al., 2019; Zhang et al., 2019; Shafahi et al., 2019), while certified approaches use verification (Zhang et al., 2018; Gowal et al., 2019; Wang et al., 2021) or randomized smoothing (Cohen et al., 2019; Lecuyer et al., 2019).
Robustness-Accuracy Tradeoff. Fundamental tension exists between standard and robust accuracy (Tsipras et al., 2019; Zhang et al., 2019; Javanmard et al., 2020; Rice et al., 2020; Schmidt et al., 2018), with mitigations via unlabeled data (Carmon et al., 2022; Raghunathan et al., 2020).
Interpretability. Robust models exhibit aligned gradients and interpretable features (Engstrom et al., 2019; Tsipras et al., 2019; Ganz et al., 2023; Srinivas et al., 2024); disentangled representations improve robustness (Yang et al., 2021; Guesmi et al., 2024).
Transferability and Compression. Examples transfer due to shared representations (Demontis et al., 2019; Wu et al., 2018); compression-robustness connections reveal capacity constraints (Ye et al., 2021; Gui et al., 2019; Xie et al., 2019; Yi et al., 2020).
Superposition and Mechanistic Interpretability. Superposition allows exponentially many features in high-dimensional spaces (Elhage et al., 2022). SAEs decompose superposed features (Cunningham et al., 2023; Bricken et al., 2023; Templeton et al., 2024; Gao et al., 2024), though computational bounds exist (Adler & Shavit, 2025).
Acknowledgments
We would like to thank Chris Olah for helpful discussions that contributed to the development of this work. We are also grateful to Michael Byun and Tom McGrath for their feedback on drafts of this manuscript.
Appendix A: Sparse Autoencoder Training Details
All SAEs were trained with a batch size of 4096, a learning rate of \(5\times10^{-4}\), and an expansion factor of \(8\times\). Activations from models trained with different epsilons had slightly different distributions. Thus, for SAE training, activations were standardized using the mean and standard deviation for that specific model computed over a subset of the training data.
When training TopK SAEs, top-\(k_{\mathrm{aux}}\) was 512 and the auxiliary loss weight was 1.
Appendix B: Toy Models of Superposition Replication
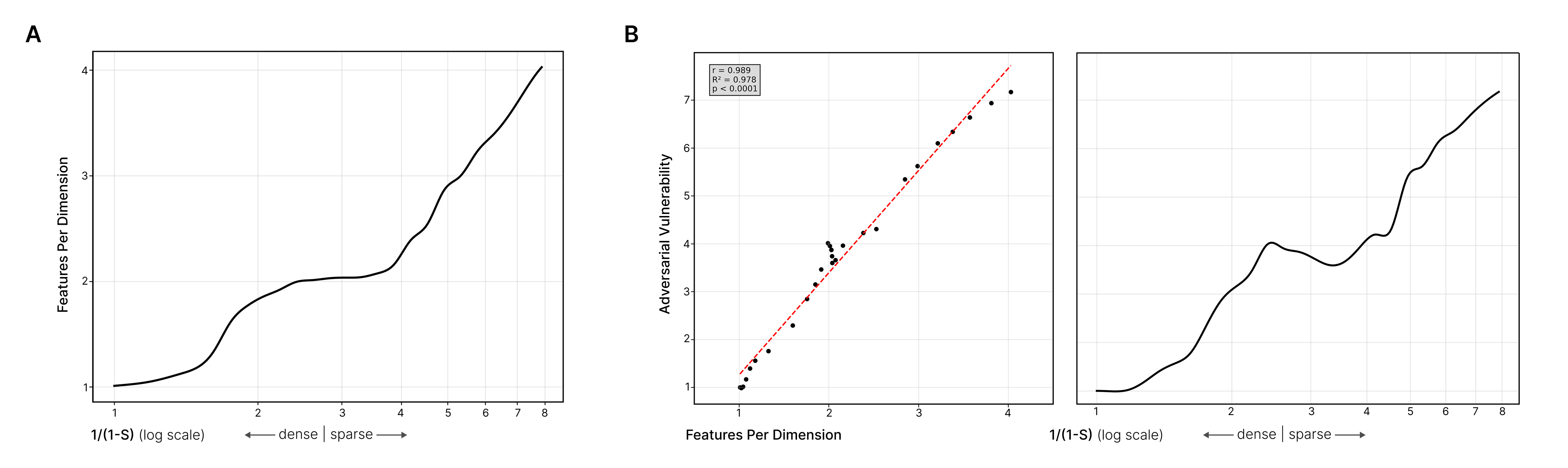
The phase transitions correspond to the onset of superposition and beyond-antipodal arrangements as described in (Elhage et al., 2022).
References
- Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., Hatfield-Dodds, Z., Lasenby, R., Drain, D., Chen, C., Grosse, R., McCandlish, S., Kaplan, J., Amodei, D., Wattenberg, M., & Olah, C. (2022). Toy Models of Superposition. Transformer Circuits Thread. https://transformer-circuits.pub/2022/toy_model/index.html
- Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., & Fergus, R. (2014). Intriguing properties of neural networks. https://arxiv.org/abs/1312.6199
- Goodfellow, I. J., Shlens, J., & Szegedy, C. (2015). Explaining and Harnessing Adversarial Examples. https://arxiv.org/abs/1412.6572
- Liu, Y., Chen, X., Liu, C., & Song, D. (2017). Delving into Transferable Adversarial Examples and Black-box Attacks. https://arxiv.org/abs/1611.02770
- Madry, A., Makelov, A., Schmidt, L., Tsipras, D., & Vladu, A. (2019). Towards Deep Learning Models Resistant to Adversarial Attacks. https://arxiv.org/abs/1706.06083
- Engstrom, L., Ilyas, A., Santurkar, S., Tsipras, D., Tran, B., & Madry, A. (2019). Adversarial Robustness as a Prior for Learned Representations. https://arxiv.org/abs/1906.00945
- Ilyas, A., Santurkar, S., Tsipras, D., Engstrom, L., Tran, B., & Madry, A. (2019). Adversarial Examples Are Not Bugs, They Are Features. https://arxiv.org/abs/1905.02175
- Rice, L., Wong, E., & Kolter, J. Z. (2020). Overfitting in adversarially robust deep learning. https://arxiv.org/abs/2002.11569
- Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., & Fei-Fei, L. (2015). ImageNet Large Scale Visual Recognition Challenge . International Journal of Computer Vision (IJCV), 115(3), 211–252. https://doi.org/10.1007/s11263-015-0816-y
- Salman, H., Ilyas, A., Engstrom, L., Kapoor, A., & Madry, A. (2020). Do Adversarially Robust ImageNet Models Transfer Better? https://arxiv.org/abs/2007.08489
- Conerly, T., Templeton, A., Bricken, T., Marcus, J., & Henighan, T. (2024). Update on how we train SAEs. In Transformer Circuits Thread.
- Gao, L., la Tour, T. D., Tillman, H., Goh, G., Troll, R., Radford, A., Sutskever, I., Leike, J., & Wu, J. (2024). Scaling and evaluating sparse autoencoders. https://arxiv.org/abs/2406.04093
- Moosavi-Dezfooli, S.-M., Fawzi, A., & Frossard, P. (2015). DeepFool: a simple and accurate method to fool deep neural networks. CoRR, abs/1511.04599. http://arxiv.org/abs/1511.04599
- Carlini, N., & Wagner, D. A. (2016). Towards Evaluating the Robustness of Neural Networks. CoRR, abs/1608.04644. http://arxiv.org/abs/1608.04644
- Croce, F., & Hein, M. (2020). Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. CoRR, abs/2003.01690. https://arxiv.org/abs/2003.01690
- Kurakin, A., Goodfellow, I. J., & Bengio, S. (2016). Adversarial examples in the physical world. CoRR, abs/1607.02533. http://arxiv.org/abs/1607.02533
- Moosavi-Dezfooli, S.-M., Fawzi, A., Fawzi, O., & Frossard, P. (2017). Universal adversarial perturbations. https://arxiv.org/abs/1610.08401
- Gilmer, J., Metz, L., Faghri, F., Schoenholz, S. S., Raghu, M., Wattenberg, M., & Goodfellow, I. (2018). Adversarial Spheres. https://arxiv.org/abs/1801.02774
- Khoury, M., & Hadfield-Menell, D. (2019). On the Geometry of Adversarial Examples. https://openreview.net/forum?id=H1lug3R5FX
- Shafahi, A., Huang, W. R., Studer, C., Feizi, S., & Goldstein, T. (2020). Are adversarial examples inevitable? https://arxiv.org/abs/1809.02104
- Shamir, A., Melamed, O., & BenShmuel, O. (2022). The Dimpled Manifold Model of Adversarial Examples in Machine Learning. https://arxiv.org/abs/2106.10151
- Mahloujifar, S., Diochnos, D. I., & Mahmoody, M. (2018). The Curse of Concentration in Robust Learning: Evasion and Poisoning Attacks from Concentration of Measure. https://arxiv.org/abs/1809.03063
- Mahloujifar, S., Zhang, X., Mahmoody, M., & Evans, D. (2019). Empirically Measuring Concentration: Fundamental Limits on Intrinsic Robustness. https://arxiv.org/abs/1905.12202
- Tanner, K., Vilucchio, M., Loureiro, B., & Krzakala, F. (2024). A High Dimensional Statistical Model for Adversarial Training: Geometry and Trade-Offs. https://arxiv.org/abs/2402.05674
- Xiao, J., Yang, L., Fan, Y., Wang, J., & Luo, Z.-Q. (2022). Understanding Adversarial Robustness Against On-manifold Adversarial Examples. https://arxiv.org/abs/2210.00430
- Zhang, H., Yu, Y., Jiao, J., Xing, E. P., Ghaoui, L. E., & Jordan, M. I. (2019). Theoretically Principled Trade-off between Robustness and Accuracy. https://arxiv.org/abs/1901.08573
- Shafahi, A., Najibi, M., Ghiasi, A., Xu, Z., Dickerson, J., Studer, C., Davis, L. S., Taylor, G., & Goldstein, T. (2019). Adversarial Training for Free! https://arxiv.org/abs/1904.12843
- Zhang, H., Weng, T.-W., Chen, P.-Y., Hsieh, C.-J., & Daniel, L. (2018). Efficient Neural Network Robustness Certification with General Activation Functions. https://arxiv.org/abs/1811.00866
- Gowal, S., Dvijotham, K., Stanforth, R., Bunel, R., Qin, C., Uesato, J., Arandjelovic, R., Mann, T., & Kohli, P. (2019). On the Effectiveness of Interval Bound Propagation for Training Verifiably Robust Models. https://arxiv.org/abs/1810.12715
- Wang, S., Zhang, H., Xu, K., Lin, X., Jana, S., Hsieh, C.-J., & Kolter, J. Z. (2021). Beta-CROWN: Efficient Bound Propagation with Per-neuron Split Constraints for Complete and Incomplete Neural Network Robustness Verification. https://arxiv.org/abs/2103.06624
- Cohen, J. M., Rosenfeld, E., & Kolter, J. Z. (2019). Certified Adversarial Robustness via Randomized Smoothing. https://arxiv.org/abs/1902.02918
- Lecuyer, M., Atlidakis, V., Geambasu, R., Hsu, D., & Jana, S. (2019). Certified Robustness to Adversarial Examples with Differential Privacy. https://arxiv.org/abs/1802.03471
- Tsipras, D., Santurkar, S., Engstrom, L., Turner, A., & Madry, A. (2019). Robustness May Be at Odds with Accuracy. https://arxiv.org/abs/1805.12152
- Javanmard, A., Soltanolkotabi, M., & Hassani, H. (2020). Precise Tradeoffs in Adversarial Training for Linear Regression. https://arxiv.org/abs/2002.10477
- Schmidt, L., Santurkar, S., Tsipras, D., Talwar, K., & Mądry, A. (2018). Adversarially Robust Generalization Requires More Data. https://arxiv.org/abs/1804.11285
- Carmon, Y., Raghunathan, A., Schmidt, L., Liang, P., & Duchi, J. C. (2022). Unlabeled Data Improves Adversarial Robustness. https://arxiv.org/abs/1905.13736
- Raghunathan, A., Xie, S. M., Yang, F., Duchi, J., & Liang, P. (2020). Understanding and Mitigating the Tradeoff Between Robustness and Accuracy. https://arxiv.org/abs/2002.10716
- Ganz, R., Kawar, B., & Elad, M. (2023). Do Perceptually Aligned Gradients Imply Adversarial Robustness? https://arxiv.org/abs/2207.11378
- Srinivas, S., Bordt, S., & Lakkaraju, H. (2024). Which Models have Perceptually-Aligned Gradients? An Explanation via Off-Manifold Robustness. https://arxiv.org/abs/2305.19101
- Yang, S., Guo, T., Wang, Y., & Xu, C. (2021). Adversarial Robustness through Disentangled Representations. Proceedings of the AAAI Conference on Artificial Intelligence, 35(4), 3145–3153. https://doi.org/10.1609/aaai.v35i4.16424
- Guesmi, A., Aswani, N. S., & Shafique, M. (2024). Exploring the Interplay of Interpretability and Robustness in Deep Neural Networks: A Saliency-guided Approach. https://arxiv.org/abs/2405.06278
- Demontis, A., Melis, M., Pintor, M., Jagielski, M., Biggio, B., Oprea, A., Nita-Rotaru, C., & Roli, F. (2019). Why Do Adversarial Attacks Transfer? Explaining Transferability of Evasion and Poisoning Attacks. 28th USENIX Security Symposium (USENIX Security 19), 321–338. https://www.usenix.org/conference/usenixsecurity19/presentation/demontis
- Wu, L., Zhu, Z., Tai, C., & E, W. (2018). Understanding and Enhancing the Transferability of Adversarial Examples. https://arxiv.org/abs/1802.09707
- Ye, S., Xu, K., Liu, S., Lambrechts, J.-H., Zhang, H., Zhou, A., Ma, K., Wang, Y., & Lin, X. (2021). Adversarial Robustness vs Model Compression, or Both? https://arxiv.org/abs/1903.12561
- Gui, S., Wang, H., Yu, C., Yang, H., Wang, Z., & Liu, J. (2019). Model Compression with Adversarial Robustness: A Unified Optimization Framework. https://arxiv.org/abs/1902.03538
- Xie, H., Yi, J., Xu, W., & Mudumbai, R. (2019). An Information-Theoretic Explanation for the Adversarial Fragility of AI Classifiers. https://arxiv.org/abs/1901.09413
- Yi, J., Mudumbai, R., & Xu, W. (2020). Derivation of Information-Theoretically Optimal Adversarial Attacks with Applications to Robust Machine Learning. https://arxiv.org/abs/2007.14042
- Cunningham, H., Ewart, A., Riggs, L., Huben, R., & Sharkey, L. (2023). Sparse Autoencoders Find Highly Interpretable Features in Language Models. https://arxiv.org/abs/2309.08600
- Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Hatfield-Dodds, Z., Tamkin, A., Nguyen, K., … Olah, C. (2023). Towards Monosemanticity: Decomposing Language Models With Dictionary Learning. Transformer Circuits Thread.
- Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., Pearce, A., Citro, C., Ameisen, E., Jones, A., Cunningham, H., Turner, N. L., McDougall, C., MacDiarmid, M., Freeman, C. D., Sumers, T. R., Rees, E., Batson, J., Jermyn, A., … Henighan, T. (2024). Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet. Transformer Circuits Thread. https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
- Adler, M., & Shavit, N. (2025). On the Complexity of Neural Computation in Superposition. https://arxiv.org/abs/2409.15318
-
Typically, features are imagined to be one-dimensional, but this can be generalized to allow more dimensions. ↩
-
We consider only uniform feature importance, causing the loss to simplify into mean squared error. ↩
-
This is a conceptual framework for building intuition rather than a formal theoretical result. The actual optimization dynamics are considerably more complex. ↩
-
https://huggingface.co/madrylab/robust-imagenet-models ↩
-
From a Popperian perspective, the hypothesis that robustness influences superposition should gain credit for predicting a surprising phenomenon, even if some alternative explanation can retrospectively be proposed. ↩