InceptionV1 was the original target model of mechanistic interpretability. That initial work largely focused on early vision, meaning the first five layers, from conv2d0 to mixed3b. This focus was partly due to the similarity of features learned in the early layers of vision models and the fact that these features are simply easier to understand (e.g., features in later layers might correspond to positioning of an object irrespective of what that object is) (Olah et al., 2020). However, as noted in that original work, polysemanticity was a persistent limitation that seems to increase as one moves throughout the layers, making later layers an impossible goal.
I have previously demonstrated that sparse autoencoders (SAEs) reveal new and more monosemantic features in early vision than studying the neurons (Gorton, 2024). But, given early vision has already been well-characterised, I wanted to validate the success of SAEs in revealing monosemantic features on a more ambitious target.
To the best of my knowledge, there are essentially no interpretable neurons on InceptionV1’s final layer, mixed5b, providing a very interesting use case for SAEs. It’s worth noting that some neurons may seem interpretable when looking at a few top dataset examples, but prior work has demonstrated this is an “interpretability illusion” that doesn’t hold when considering examples across the activation spectrum (Bolukbasi et al., 2021).
As to why that might be when features were previously found in early vision, it seems plausible that superposition becomes much more prevalent across the model as the features become less general (e.g. a single curve) and more specialised (e.g. a dog face with specific colouring), with these specialised features being sparser and requiring a larger number get represented in each layer.
I will largely use the methods of my previous paper with two slight modifications:
- I train across the entire layer rather than on specific branches.
- I use a expansion factor.
Notation: to be explicit, when I say feature I mean feature learned by a sparse autoencoder. I also refer to features like mixed5b/f/[id] and neurons like mixed5b/n/[id]
Summary of Results
- Sparse autoencoders provide interpretable features that cannot be recovered by studying the neuron basis.
- Features are largely monosemantic but likely are still too coarse and would benefit from a higher expansion factor.
- Features in mixed5b are very class-specific, representing different aspects (“facets”) of the output classes.
- Features can be used to produce interpretable circuits.
- Representation space appears at least superficially hierarchical.
Overview of Features

mixed5b SAE alongside their most similar neuron. For each feature and neuron, dataset examples at varying activation levels and a feature visualisation are provided.Figure 1 presents three features from mixed5b with each being quite interpretable across the activation spectrum. For example, mixed5b/f/32 is detecting some specific subtype of bird. Low activations of less than 30% of the maximum still are from birds, just ones less like what the feature is detecting. Images that don’t contain birds consistently produce no activation of this feature. Compare that to the most similar neuron, mixed5b/n/706, where not only is the feature visualisation nonsensical, the dataset examples also don’t provide further clarification, with the max activation including unrelated concepts such a baseball, a bird, and someone eating a banana.
The feature visualisation for mixed5b/n/640 is slightly more interpretable, revealing obvious polysemanticity. The bottom right quadrant appears to contain a bird and the top right. Although not cleanly the case for this specific neuron, as mentioned earlier, polysemantic neurons can look monosemantic when considering only the top dataset examples (Bolukbasi et al., 2021). This can be seen to some extent here, where two of the four top dataset examples contain a bird with similar colouring to the feature visualisation, and even the monkey contains the yellow body. But, as soon as one looks below the 90% threshold, this trend does not hold at all, and it can be seen this neuron is likely even more polysemantic than the feature visualisation implied.
Feature-Based Circuit Analysis
Similarly to how prior work is able to use neurons to understand circuits (Cammarata et al., 2020), features can be used in their place. This is particularly useful for a layer like mixed5b where it provides causal insight into InceptionV1’s labelling that was previously impossible.
This can be done via:
where are the decoder weights from , are the decoder weights for the preceeding layer , and are the InceptionV1 weights from to .
is a tensor and so instead of performing a traditional matrix multiplication, I multiply out the dictionary vectors via a convolution.
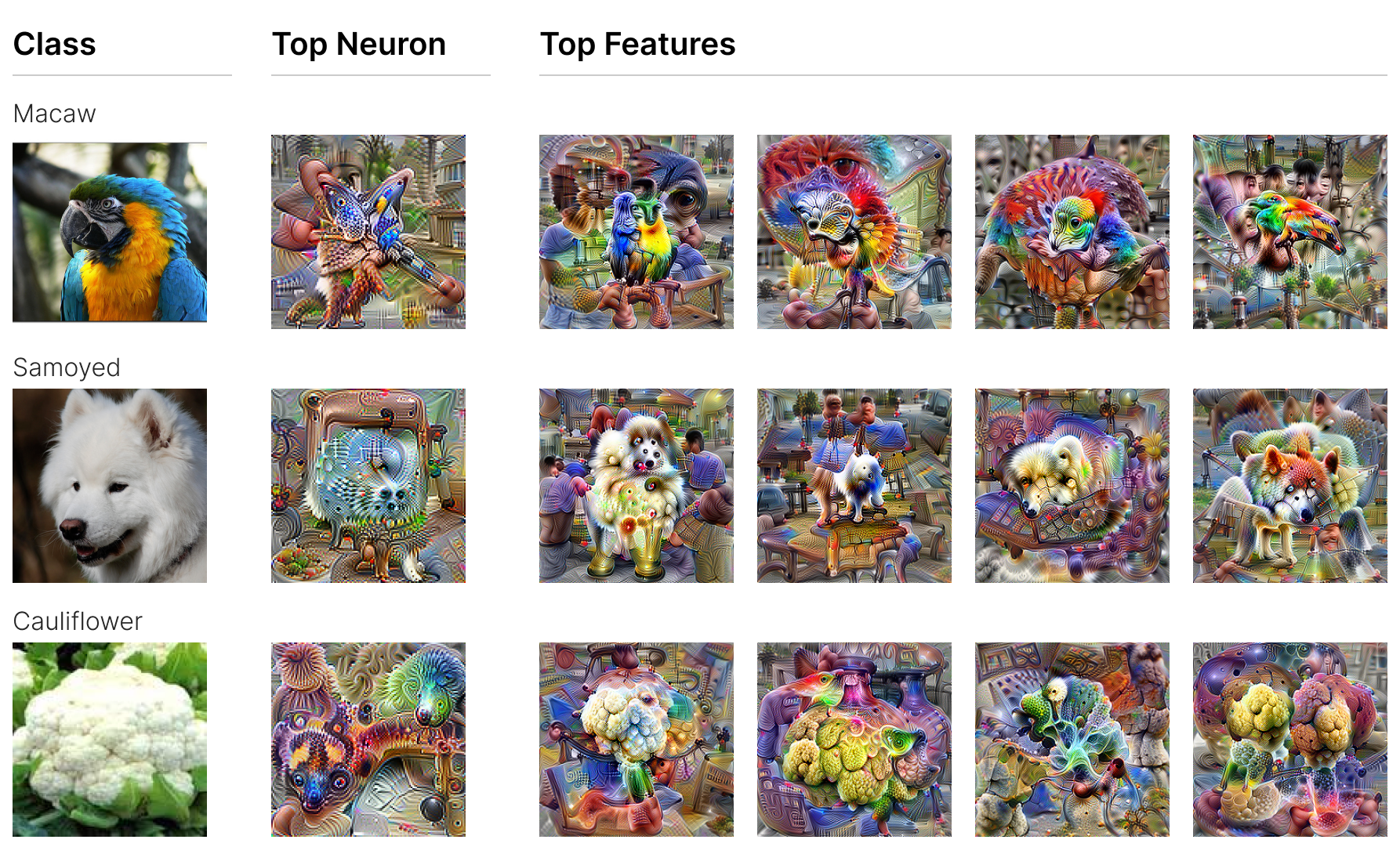
Figure 2 demonstrates how much more interpretable the top feature weights are when compared to the neuron weights, providing a more useful look at the weights to each class.
Features as Facets of an Output Class
A reasonable hypothesis for what mixed5b would attempt to represent is that of “facets” (Nguyen et al., 2016), using superposition to represent many aspects of a different output class. The “grocery store” class is an obvious example of what is meant by a facet. Although a single concept, it can be broken down into multiple components. For example, the outside of the store, the checkouts, and the produce section. Despite visually being different and not necessarily occurring simultaneously in a image, should increase the likelihood of a given imagine being a grocery store.
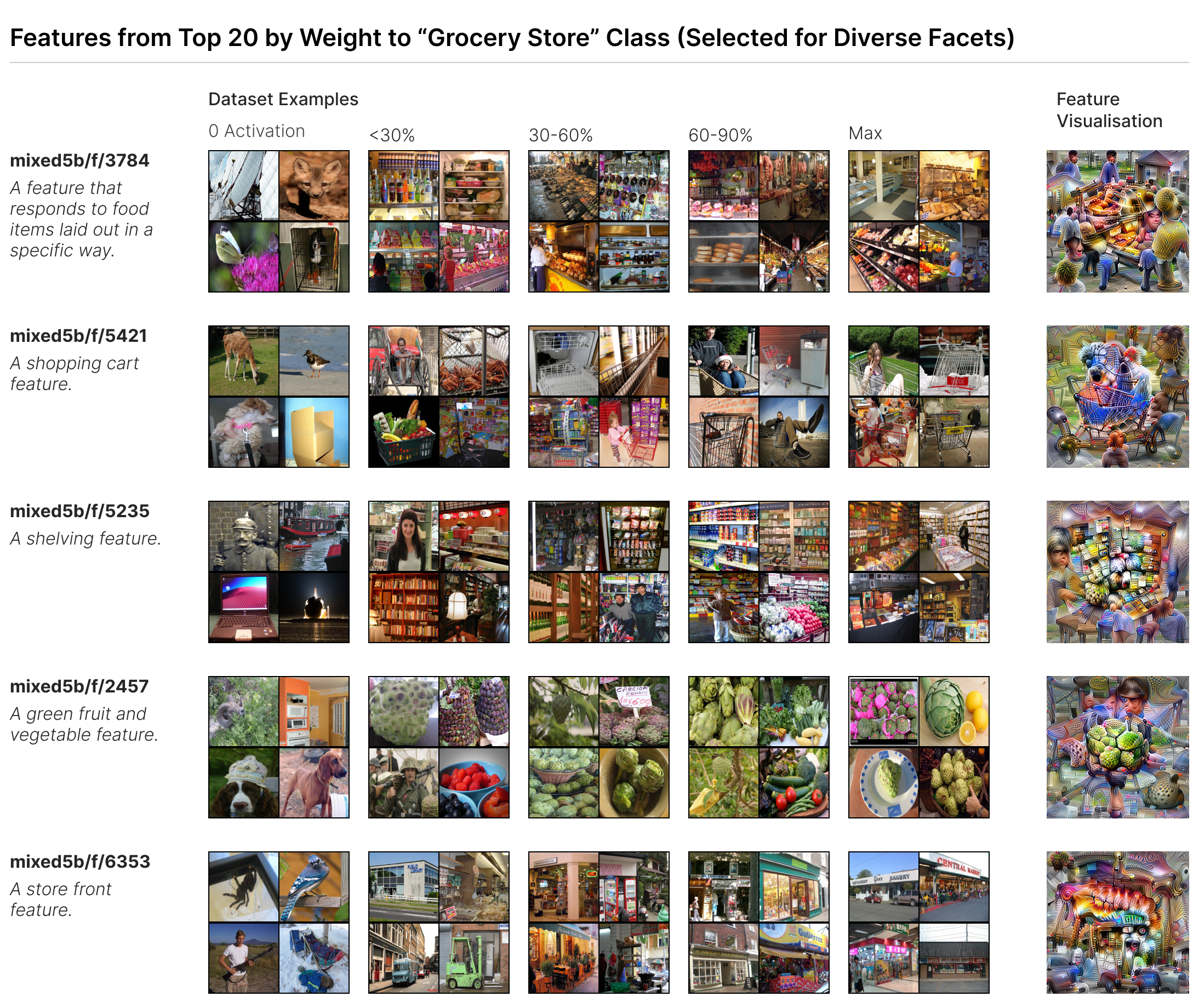
mixed5b capture different aspects of the classes.Looking at the weights of mixed5b features to the grocery store class, as shown in Figure 3, it is apparent that the facet hypothesis does seem to hold. From top-to-bottom we can see:
- A feature that responds to food items laid out in a specific way.
- A shopping cart feature.
- A shelving feature.
- A green fruit and vegetable feature.
- A store front feature.
mixed5b/f/6353, the store front feature, does appear to respond to stores that aren’t just grocery stores (e.g. bookstores). I suspect this is likely a result of the expansion factor not being sufficiently high and thus we see coarser features than the model would actually represent.
Simple, Two-Layer “Brittany Spaniel” Circuit
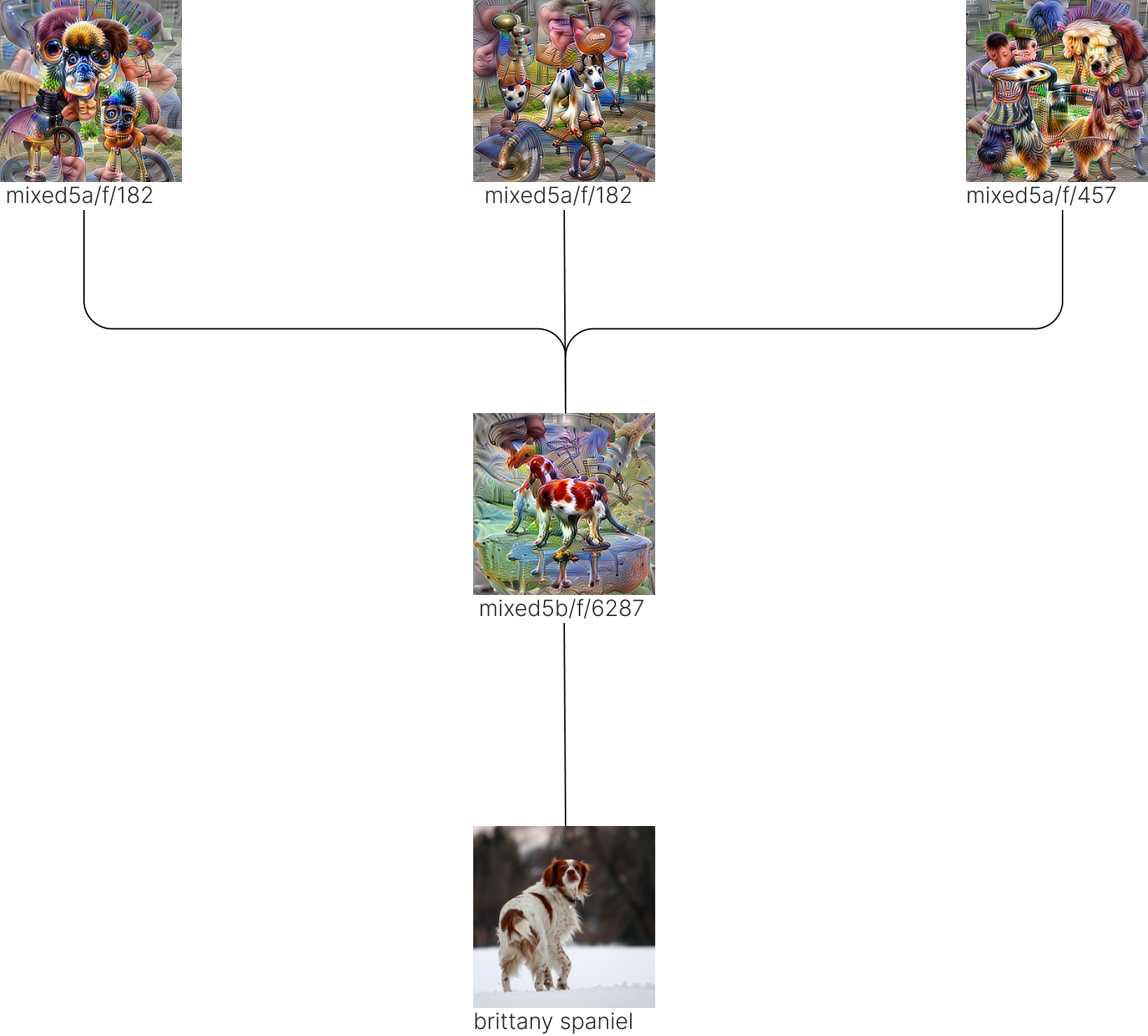
mixed5a and mixed5b to the 'brittany spaniel' class.An issue that quickly becomes apparent when doing circuit analysis even across only a handful of layers (e.g. classes → mixed5b → mixed5a) is how quickly these become overwhelmingly large. I’ve prepared a simple circuit in figure 4 to demonstrate that this works but note that even for this one class, including all positive weighted features would be notably larger and more informative.
In figure 4, mixed5b/f/6287 still appears very specialised to the “brittany spaniel” class with the feature seemingly representing a dog body with the characteristic orange and white colouring of the breed. The mixed5a features are more generic dog features or possibly coarser versions of the colouring in the case of mixed5a/f/182.
Representation Space Structure
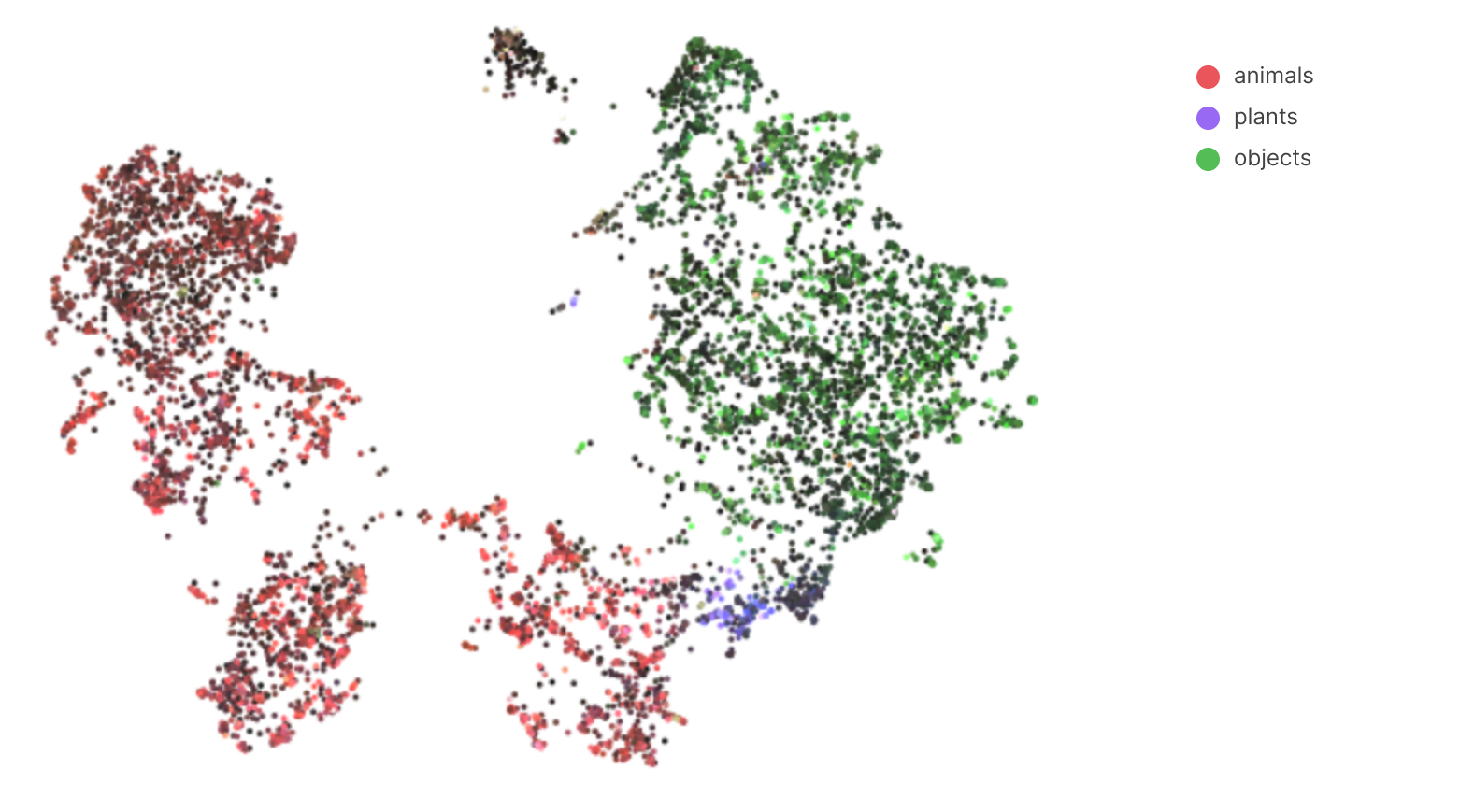
mixed5b reveals that features organise themselves according to a very broad hierarchy.Features organise themselves in a clear hierarchical structure, forming distinct clusters of related concepts. Figure 5 reveals that features organise themselves into three broad categories - animals, plants, and objects.
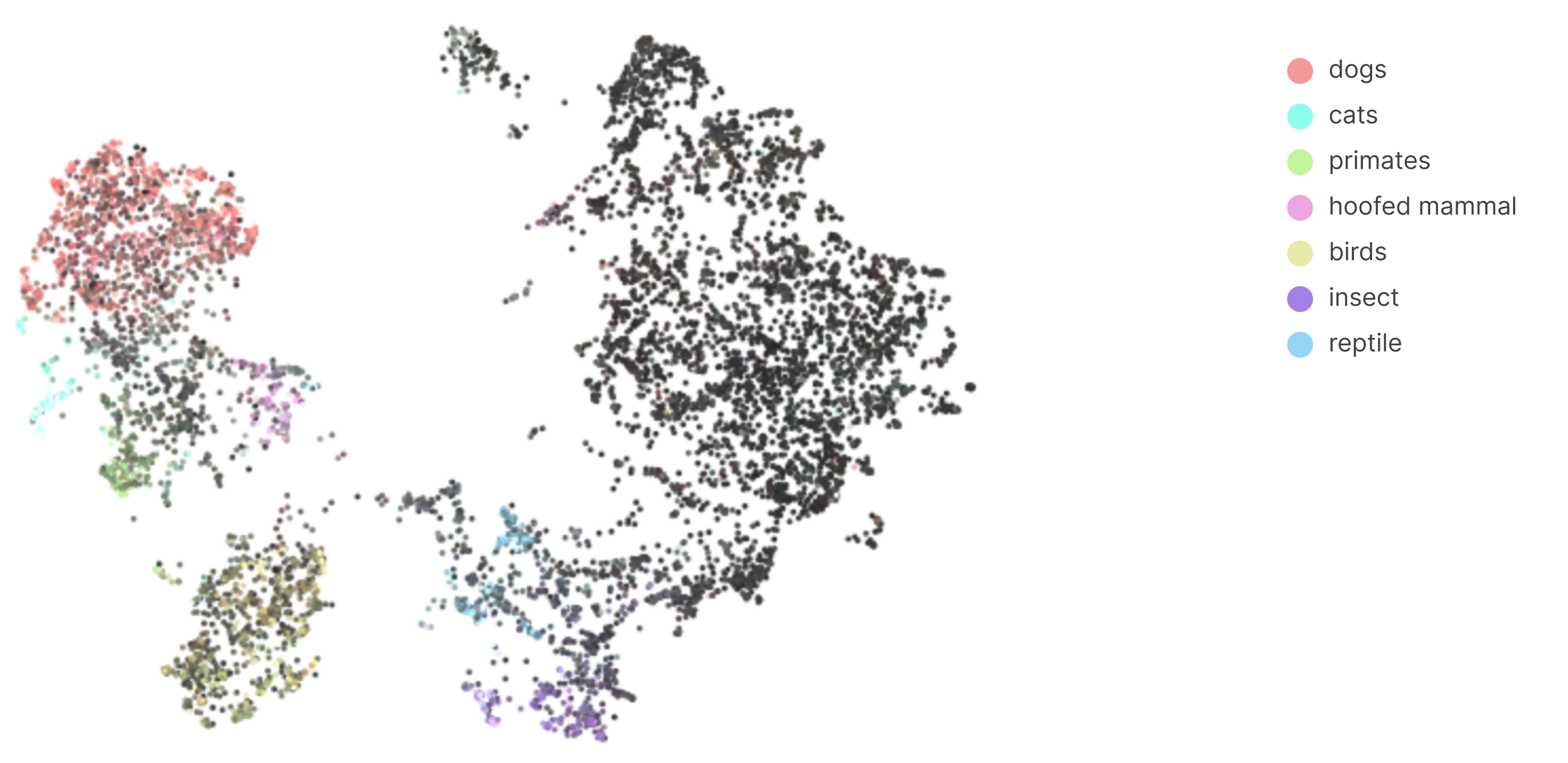
Figure 6 shows that, as we move further down the semantic hierarchy of the broad animals category, meaningful structure is preserved. Not only are relevant features, such as those related to dogs, close to one another, related animal types, such as mammals, also maintain this property.
Conclusions and Next Steps
Sparse autoencoders have allowed me to extract interpretable and relatively monosemantic features from InceptionV1’s final layer, mixed 5b, for the first time. Although preliminary, this is a really promising signal of their likely success across all of InceptionV1.
This working doesn’t mean that the project of understanding InceptionV1 is complete. The features I show here are not perfect and there’s a lot that might improve them. There are still a number of open research problems (e.g. recovery of rare features, understanding feature manifolds). In the short-term, there are some engineering projects I should undertake to improve feature quality and iteration speed on this work:
- Train better SAEs.
- It’s quite remarkable how well vanilla SAEs work! But since the updates I incorporated (Conerly et al., 2024) there have been a number of improvements on SAEs and these might produce better features.
- Train at a larger expansion factor to get more granular features.
- Improve analysis pipelines. Now that I’m working with a lot of features, there is a barrier of manual inspection not scaling very well.
- Automated interpretability (Bills et al., 2023). It would be interesting to see how well this works in and of itself and then if it works, it would provide me a lot of value.
- Better dashboards, possibly resembling the OpenAI Microscope or the InceptionV1 weight explorer of Olah et al. (2020) would speed up work immensely.
References
Nguyen, A. M., Yosinski, J., & Clune, J. (2016). Multifaceted Feature Visualization: Uncovering the Different Types of Features Learned By Each Neuron in Deep Neural Networks. CoRR.
Bills, S., Cammarata, N., Mossing, D., et al. (2023). Language models can explain neurons in language models.
Bolukbasi, T., Pearce, A., Yuan, A., et al. (2021). An interpretability illusion for bert. arXiv preprint arXiv:2104.07143.
Cammarata, N., Carter, S., Goh, G., et al. (2020). Thread: Circuits. Distill.
Conerly, T., Templeton, A., Bricken, T., et al. (2024). Update on how we train SAEs.
Gorton, L. (2024). The Missing Curve Detectors of InceptionV1: Applying Sparse Autoencoders to InceptionV1 Early Vision.
Olah, C., Cammarata, N., Schubert, L., et al. (2020). An Overview of Early Vision in InceptionV1. Distill.